This is project aims to utilize all Data Science Concepts learned in the IBM Science Professional Course. We define a Business Problem, the data that will be utilized and using that data, we are able to analyze it using Machine Learning tools. In this project, we will go through all the processes in a step manner from problem designing, data preparation to final analysis and finally will provide a conclusion that can be leveraged by the business stakeholders to make their decisions.
TABLE OF CONTENTS
- Introduction
- Target Audience
- Data Overview
- Methodology
- Discussion
- Conclusion
1. Identifying the Business Problem (Introduction)
Ho Chi Minh City have the largest population in Vietnam. This area has many opportunity. It attracts people from many places. This city has about 9 million people. It have variety cultures.
Example : Chinese, Indian, Khmer, Cambodian, Laos... HCM city being the hub of interactions between ethnicities many opportunities for entrepreneurs to start or grow their business.
The objective of this project is to use Foursquare location data and regional clustering of venue information to determine what might be the 'best' place in Ho Chi Minh city to open a coffee shop. Coffee is one of the most drink in Vietnam. Through this project, we will find the most suitable location for an entrepreneur or business owner to open a new coffee shop in Ho Chi Minh city, Vietnam.
We need to clarify the differences between a coffee shop and café.
Coffee shop has no similar connotations.
From personal experience in United States, a café serves meals, while a coffee
shop usually just sells snacks ( muffins, scones, shortbread ). This is not
strictly the case and both usually serve coffee. In this project, we suppose to
work only on the café.
Although there are already a lot of cafés in Ho Chi Minh City,
their density between district is not uniform. There are some districts
containing too many café while there are less in some others. If we have some
knowledge about population, the price house in each districts coupling
with an overview of the number of café,
we can have a better idea to set up a new business there.
 |
| Figure1: Photo from theculturetrip.com |
2. Target Audience
This project is aimed towards Entrepreneurs or Business owner who want to open a new coffee shop or grow their current business. The analysis will provide vital information that can be used by the target audience.
3. Data Overview
The data that will be required will be a combination of CSV files that have been prepared for the purposes of the analysis from multiple sources which will provide the list of price house from my github which this have crawled from website batdongsan.com. And Geographical location of district in Ho Chi Minh city from my github. And Venue data pertaining to coffee shop ( via Foursquare ). The Venue data will help find which neighborhood is best suitable to open a new coffee shop.
- Source 1 : The price house in Ho Chi Minh City.
- Source 2 : The demographic of Ho Chi Minh city
- Source 3 : Name of the wards in each district.
Source 1: The price house in Ho Chi Minh City.
 |
| Figure 2: Price house in HCM city show in this page |
The mogi.vn site shown above provided about the price house in HCM city. Its includes the name of district and price house of this district. Since data is not in format that is suitable for analysis, scraping of the data was done from this site (show in figure 3).
Figure 3 : Data was scraping from mogi.vn site and put into pandas dataframe.
Source 2 : The demographic of Ho Chi Minh city.
 |
| Figure 4 : Wikipedia site about demographic of HCM city ( year 2015 ) |
1. Link : https://en.wikipedia.org/wiki/Ho_Chi_Minh_City#Demographics
The wikipedia site shown above provided about the demographic in HCM city. Its includes the name of district, the quantities of ward is located in each districts, area, total population, Density, . Since data is not in format that is suitable for analysis, scraping of the data was done from this site (show in figure 5 ).
 |
| Figure 5 : Data was scraping from wikipedia and put to dataframe |
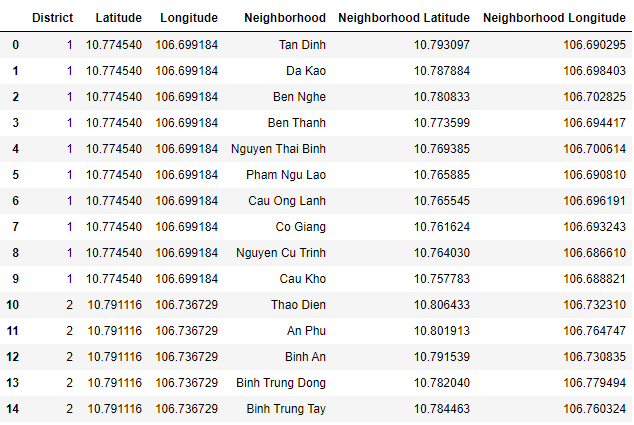
Source 3 : Name of the wards in each district
 |
| Figure 6 : List the ward of each district ( hochiminhcity.gov.vn) |
This link provide list the ward of each district. It include the name of district, name of the ward. Since data is not in format that is suitable for analysis, scraping of the data was done from this site (show in figure 7 ).
 |
| Figure 7 : ward of each district |
4. Methodology
First all, we need collected the
data by scraping the table price house on mogi page and the population of each
district in HCMC on the wikipedia page. The BeautifulSoup
package is very useful in this case.
The column District is process Vietnamese and replace word ‘Quan’ and delete
space before and after the string ( use strip() in this case )
Throughout the project, we use numpy and pandas packages to manipulate dataframes.
We merge table price house vs table
population base on District. (Main
data frame )
 |
| Figure 8 : Merge price_house_df vs population_df |
We using geopy.geocoders.Nominatim to get the coordinates of districts and add them to source 1.
 |
| Figure 9 : Using geocoder get coordinates of the district |
We use folium package to visualize the HCMC map with its districts. The
central coordinate of each district will be represented as a small circle on
top of the city map.
 |
| Figure 10 : Visualize the districts in HCM city |
Then, we need collected the data to the table
ward. It include name of districts, ward of each district on
pso.hochiminhcity.gov.vn. The BeautifulSoup package is very useful in
this case.
 |
| Figure 11 : the wards of each district |
We use Google Place API to get the
coordiantes of the wards of each district. ( Source 2 )
 |
Figure 12 : the coordinate of the ward in each district
|
We use folium package to visualize the HCMC map with the wards. The
central coordinate of each district will be represented as a small circle on
top of the city map. |
Figure 13: Visualize the wards in each district
|
We use
Foursquare to get venue around the wards of each district. ( Source 3 ) |
| Figure 14 : The venue around of the wards |
5. Discussion
5.1 The venues
 |
Figure 15: Number venues of each
district ( this is sum all venues of the
wards of each district in HCM city) |
 |
Figure 16 : Number categories of each
district
|
In this time, the Tan Binh, Phu Nhuan instead the
position of 5 vs 10. District 1 vs 3 are still very diversity. The reason for
that, there are many venues but the categories in some districts is maybe there
some principle categories in these district. Those principle categories play
the major role in the commercial activities of these districts.
we grouped those rows by District and by taking the count all venue of each District.
 |
| Figure 17 : Grouped District by the count all the venue. |
Now, we calculated top 5 categories popular in HCM city.
 |
| Figure 18 : Top 5 Categories popular in HCM city |
Then, In the
table above, Vietnamese Restaurant (766), Café (736), Coffee Shop (384),
Seafood Restaurant (219), Asian Restaurant (215). The café is main category in
the drink business with 736 different venues.
 |
| Figure 19 : Top 10 Categories common in each district |
Base on the table above, for less competition, we
can choose district whose first top
common venues is not Café. For example : 1, 10, 2, 3, 4, 5, 7, 9...etc.
Then to analyze the data we performed a technique in which Categorical Data is. Data is transformed into Numerical Data for Machine Learning algorithms. This technique is called One hot encoding. For each the Districts, individual venues were turned into the frequency at how many of those Venues were located in each District.
 |
| Figure 20 : One hot encoding |
Then we grouped those rows by Neighborhood and by taking the average of frequency of occurrence of each Venue Category.
 |
| Figure 21 : Grouped District by the average of the frequency of each venue. |
Now, we retrieved data to relate Café. For to create Café table.
 |
| Figure22 : Café table |
K-Means Clustering
 |
| Figure 23 : Finding the K vs Error |
Then we used a model the accurately pointed out the optimum K value. We imported 'KElbowVisualizer' from the Yellowbrick package. Then we fit our K-Means model above to the Elbow visualizer.
This give the model below:
 |
| Figure 24 : Finding the right K using the Elbow Point |
We just integrated a model that would fit the error and calculate the distortion score. From the dotted line, we see that the Elbow is at K = 5. Moreover, in K-Means clustering, objects that are similar based on a certain variable are put into the same cluster. Districts that had a similar mean frequency of Café were divided into 5 clusters. Each of theses clusters was labelled from 0 to 4 as indexing of labels begins with 0 instead of 1.
 |
| Figure 25 : Appropriate Cluster Labels were added |
After, we merged the table above with source 2 to creating a new table which would be the basis for analyzing new opportunities for opening a new coffee shop ( café ), in Ho Chi Minh City. Then we created a map using the Folium package in Python and each neighborhood was coloured based on the cluster label.- Cluster 1 : Very Low
- Cluster 2 : Low
- Cluster 3 : Medium
- Cluster 4 : High
- Cluster 5 : Very High
Now, we merge cluster labels with main data frame.
 |
| Figure 26 : main data divided the cluster |
But, we only focus to cluster 1,2,3,4 . The places has Cafe which is not 1 st common venues.
 |
| Figure 27 : Data clarified the cluster |
5.2 Price House of each District in Ho Chi Minh City
Look back to the Price House ( PH), we categories them into 4 group ( unit : million VND / m2 ). We need focus on the Price House Low and Medium to set up our business.
- Low : 30 < PH <= 100
- Medium : 100 < PH <=200
- High : 200 < PH <= 300
- Very High : PH > 300
 |
| Figure 28 : Visualize the cluster with bar chart |
Data frame after clarify.
 |
| Figure 29 : Dataframe clarified the price house |
5.3 Density of each District in Ho Chi Minh City
Look back to the Density, we categories them into 3 group ( unit : person / km 2 ). We need focus on the Price House Medium and High to set up our business.
- Low : Density < 16767
- Medium : 16767 <= Density < 31174
- High : Density >= 31174
 |
| Figure 30 : Visualize the cluster with bar chart |
Data frame after clarify.
 |
| Figure 31 : Dataframe clarified the density |
- Café very low + PH medium + Density medium : Binh Thanh, Tan Binh.
- Café low + PH low + Density medium : Go Vap.
- Café low + PH medium + Density high : Phu Nhuan.
- Café high + PH low + Density high : 4.
- Café high + PH low + Density medium : 8.
- Café high + PH medium + Density high : 6.
6. Conclusion
So we found Phu
Nhuan district where is the best suitable place. Its include amount of café
Low, Price House Medium, Density High. But, we can choice the rest place in
this above table.
























{kind=link}
{kind=link}
{kind=link}
Comments
Post a Comment